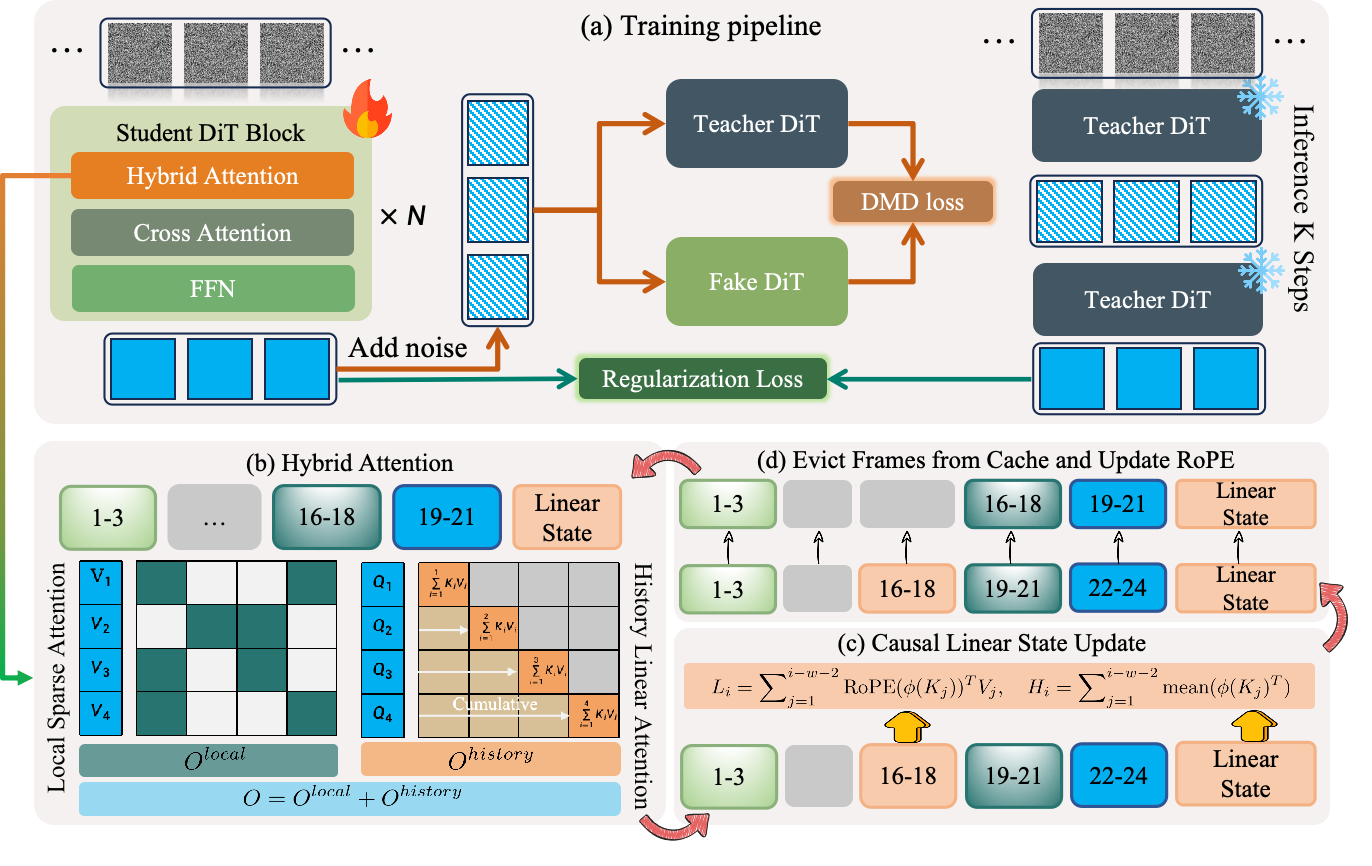
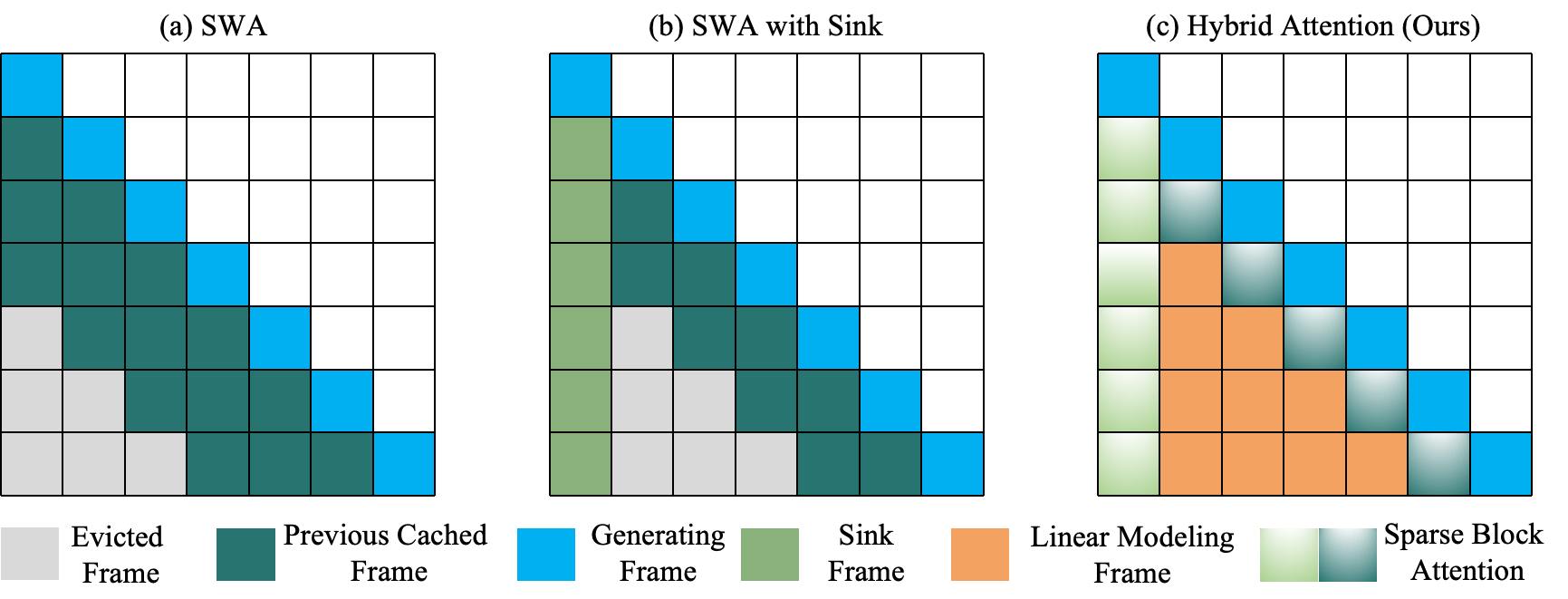Illustration of our hybrid attention paradigm for SVG. (a) The standard SWA approach only caches the most recent frames, leading to significant error accumulation in long-form generation. (b) While sinking the first frame can reduce early drift, it sacrifices motion diversity and fails to capture long-horizon dependencies effectively. (c) Our hybrid attention combines long-term history retention with efficient local modeling, leveraging low-cost history linear modeling and sparse SWA to enhance performance.